

Attempting NoCode, let's talk strategy
Okay, let's recap from my previous post, to assure minimal operational work and to support pay as you go we made a choice, and it is a big one.
We go serverless!
Our core feature is visual coding, let say hypothetically, we have a definition language in where we can model domain concepts that can be stored as JSON. The big question is, how do we convert this model into a running application?
Do we have options?
Well, yes we have, we can choose between model interpretation or code generation, but what does this mean?
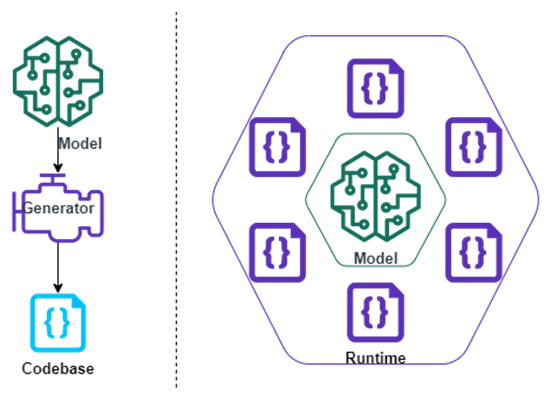
Model interpretation
Essentially, building a generic engine, a runtime if you will. A runtime can load a model and interpret the desired behavior. In other words, configure generic objects to do as you please. Runtimes excel at flexibility and portability, with the condition that the runtime is built in a portable language e.g. Java.
Because model and code are loosely coupled you can benefit from easy deployments, hot reloads, and model debugging at runtime. Powerful stuff.
Code Generation
You write code that writes code. An active code generator will convert a definition into runnable (final) code, this means generated sources should never be altered. If there are problems with the generated code, the issue should be fixed in the generator or model. A code generator excels in simplicity and readability regarding the running application
What to do?
We have two great options, what should we do.
There are no solutions. There are only trade-offs - Thomas Sowell
So, no good answer, which one is the least worse? We start with stating the important stuff, at least, the things we find important.
Priorities, our guiding design principles
Yes, they are in order, here we go.
1. Code Transparency
Well, the post's title give's it away, attempting NoCode. Even if you implement model-driven development, what NoCode in essence is, there will be code. This code will reflect your business domain and therefore you should trust that the code will do what you designed it to do. Making sure the application and underlying code can be reasoned about is the foundation to build trust. Code transparency is a manner to enable reasoning.
2. Serverless first approach
The first decision we made was, serverless all the way. Mainly because we want to minimalize the operational burden and focus on creating functionality. A full cloud-native approach enables us to do just that.
3. Visual coding concepts
Yeah, this one is a given when building a NoCode platform. But it is good to mention it explicitly. Notice it is not our top priority? So, why?
It has to do with our philosophy, we believe that your model also means your code. So when a trade-off between transparency or visual concept has to be made during our platform design, transparency should win, always. We can't predict the future, we make it up as we go. And with that in mind, it isn't unthinkable that down the line a customer acquires the need for custom code. At that point, should it be discouraged, challenging, or just transparent? I know what I would want, seamless integration between custom en generated code. It is good to have your priorities straight, right?
Practicality, start small
Not a design principle perse, just common sense. Whatever we do, we should be able to start small. We are interested in building walking skeletons before we add the muscles and skin. No point in painting racing stripes on your car if the engine is not connected to the wheels.
Trade-off time
So, interpretation or generation, who has the better fit? We looked at a couple of characteristics and assigned a relative score, as you can see in the graph both options are equally good (they have the same area) but they have different centers of mass. It is good to know that a comparison like this is not an exact science, it is opinionated by experience, knowledge, and lack of knowledge. Because you have to find a balance between innovation and comfort. With more innovation than you need, you are going to have a bad time.
Serverless Fit
To assign a score here, you have to have a basic understanding of what FaaS is. We chose AWS Lambda, Anatomy of AWS Lambda describes in an accessible way in broad strokes how AWS Lambda works. For our comparison, it is good to know that every function gets a dedicated runtime which is started just in time but may have an extended lifespan to handle consecutive invocations. You don't know when, but at some point, your runtime is garbage collected.
With this in mind, we can conclude that for our use case fast startup times are more imported than raw runtime performance. With model interpretation, we do the heavy lifting during runtime startup where with code generation we do the heavy lifting during the build step. Therefore we believe that code generation has a better fit with serverless.
Portability
Can you move your solution to another cloud or even on-prem? And this is where a runtime shines if you use a portable language like e.g. Java you could run your solution anywhere. This is of course also true for a generator, but when you opt for a generator, chances are you did this because you wanted to generate something specific. It is not a coincidence that we positioned portability opposite of serverless fit on the same axis.
Simplicity
Can you reason about your code, that is the criterion we use to determine if a code project is simple or not. It is the difference between subtext or implicit text. Using runtime magic like reflection and extension of highly reusable building blocks is in my opinion subtext, almost esoteric, it demands a deeper knowledge of the runtime to be able to reason about behavior. Code generation is implicit text, the magic is in the generator and at runtime, you have code that can be reasoned about with "standard" software engineering knowledge.
That's why we score code generation higher for simplicity.
Flexibility
Or, in other words, can you build everything you can imagine with this solution. Again, it is not a coincidence that we positioned this criterion opposite of simplicity. Simplicity comes with a price, with runtime magic the possibilities are endless.
Evolvability
With this criterion, we focused on iterability. Building a runtime is not an easy task, furthermore, you need a good chunk of your solution to get a running application. Opposite, with a generator you could start with what you know, building an application by hand, and extract patterns you recognize and automate these. If you want to introduce new features you could do the same thing, build it by hand, recognize and automate.
Model debugging
The downside of code generation is that you always have to perform a build step to verify your model is valid. Schema validation can be used for model debugging, but this is not a fail-safe method. Your schema may lie, the generator doesn't. Therefore we think that model interpretation has better support for model debugging because you could do it live at runtime.
What was important again?
We stated that code transparency, serverless fit, and starting small are very important for us. A generator shines at these criteria so that is the solution we picked. There is no free lunch, so we have to accept that our solution will be less portable, flexible and we may have some extra complexity regarding model debugging.
Although we do accept these "downsides" we see some mitigating measures we could take to ease "the pain".
To handle flexibility, we are not puristic in generating everything, we do foresee some library code to handle e.g. database access. We build a little bit off runtime to support our applications, it is important to know this is only conceptual compression and not model interpretation. So we are okay with that.
To handle portability, we will consider using a microkernel architecture for our generator. We will not build this right away, but when decisions have to be made we will keep in mind that this may become a requirement in the future.
To handle model debugging we will use schemas to validate all models, not foolproof, but acceptable.


