Draw The Line
Bubbles of complexity
We use serverless techniques to handle unpredictable loads while keeping operational costs to a minimum. Nothing in life is free, and we do pay in complexity.
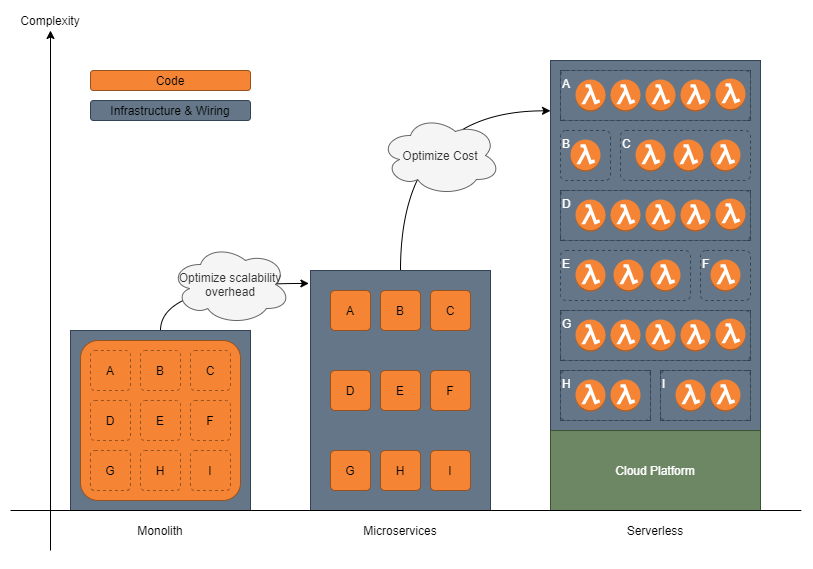
We tackle this complexity by making sure that the technology supports the design and not the other way around, my previous post mentioned we use majestic monolithic thinking to design our applications and merge this with serverless concepts by using an event-driven architecture. Our latest version of the generator uses a monolithic model as input, generates code, packages this code as microservices, and deploys it as function as a service. This approach compresses the conceptual complexity away from our business domain, but there is another disadvantage in event-based systems that needs solving.
Event-based means goodbye call stack! The architect's dream regarding loose coupling may as well be the developer's nightmare to debug. It introduces a lot of uncertainty regarding failure. Can we pinpoint the component that failed? Where are the logs? How do we set up proactive monitoring, and then what? Amazon Web Services (AWS) does provide a managed service to set up monitoring, it is called X-ray. But that is where we drew the line so to speak.
The thing we try to do is quite ambitious, venturing out into another realm of complexity does not sound like a good idea. Truth be told, analytics and monitoring is not our core competence. We decided we didn't want to pay the opportunity cost to learn how to do it ourselves... We "buy" it.
Finding a vendor that sells Observability
Everyone is giving out free samples, and that is how our quest began. The first platform we tried was bluematador.com, a good solution but not the right fit for us. Not a good fit for the same reason that Data Dog didn't feel right, the "problem" with these first two solutions is that you could measure practically anything you want, especially with Data Dog. Very impressive stuff, the thing is, more bells and whistles mean you have a steeper learning curve. This is fine if you're into big data analyses. But adding an extra bubble of complexity is something we want to avoid, we are looking for intuitive distributed tracing with minimal setup. Intuitive is a broad spectrum, so let me clarify. We are looking for a product that delivers distributed tracing for serverless applications on AWS that has minimal setup and is intuitive to use for two developers with a Java background in a Service-Oriented environment. So, we are looking for something more opinionated, and that is when we landed on Dashbird.io and Lumigo.io.
Both products are easy to set up and use, but we felt that Lumigo was more opinionated in how you should build a serverless application on AWS, which drew us over.
We are happy with our choice and found some nasty bugs in our code with the provided tooling, and even re-architected our GraphQL API. Are we ever going to use AWS's X-Ray? Well, I don't know, but for the foreseeable future, Lumigo is our monitor.
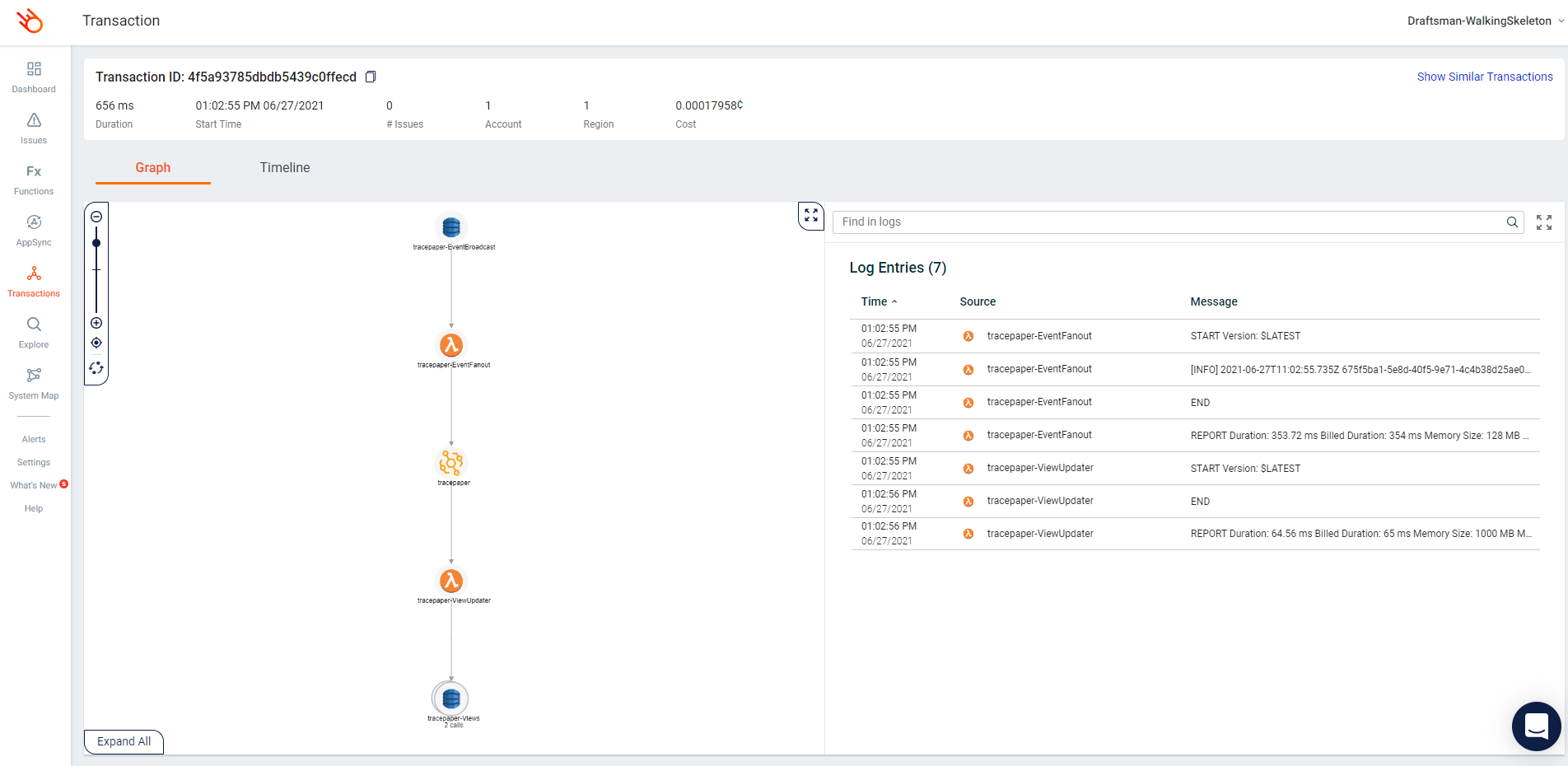
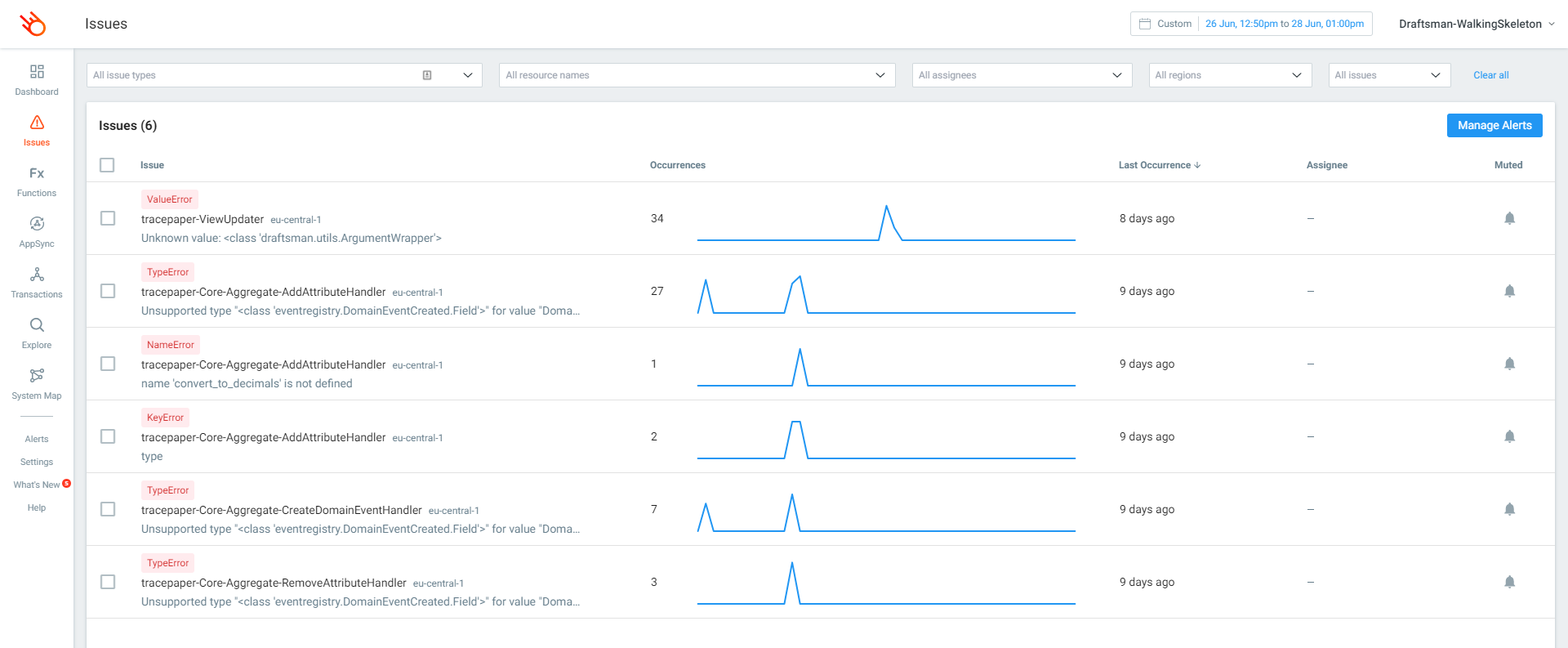
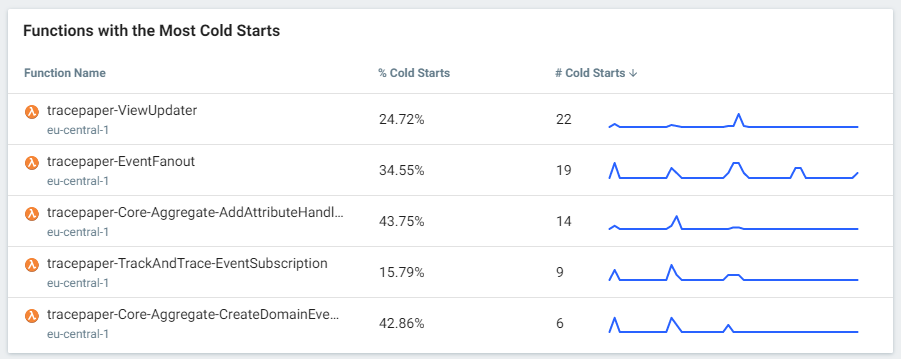
As I sign off for this weeks blogpost, I will leave you with some screenshots from Lumigo so you can see why we are so enthusiastic about this tool. Until next time.