A new feature and Why we need a KeyChain
First of all, it's been a while for multiple reasons. Work, life, and the need to spend free time with friends and family.
The most joyous reason to not spend time alone with a computer screen is the birth of my son :)
But my son likes to sleep a lot, and preferably he cuddles up inside a baby pouch close to mom or dad. So sitting here as a marsupial and listening to soothing white noise, maybe this is a good time to pick up writing again.
Efforts on Tracepaper did not stop altogether, we just entered eco-mode, nonetheless, we can announce a new feature:
You can now rename the resources you previously modeled in Tracepaper!
I'm fully aware this sounds lame AF, but hear me out it gets better. To understand why renaming stuff is not trivial you need insight into the segregation between read and write models that we use inside Draftsman Generated Applications.
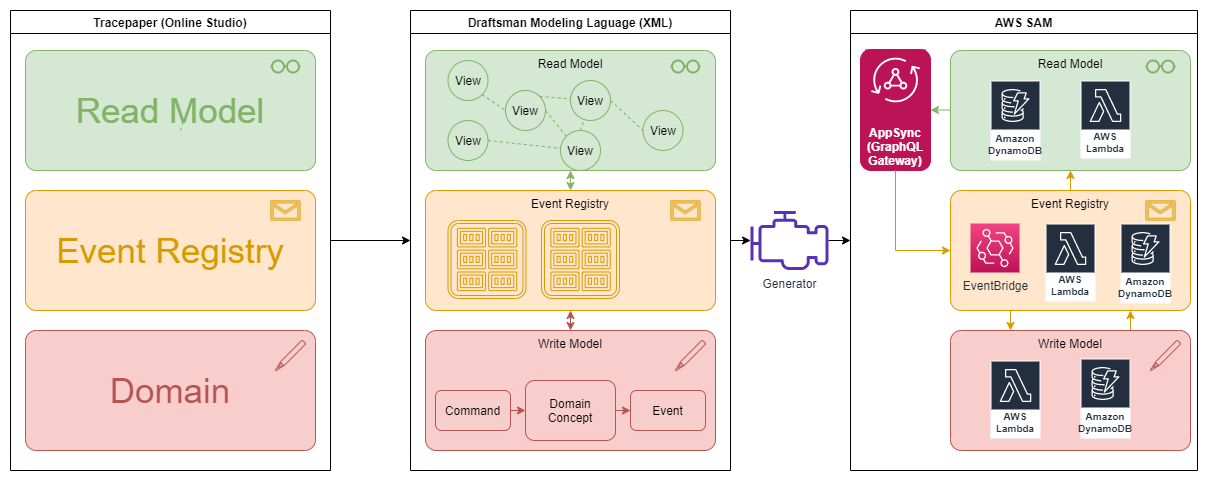
Let's start with the read-model (the green stuff ), the read-model is data-driven. Clients query this model for their data needs. We have to look at implementation details to understand some limitations. One of our guiding principles is serverless first to minimalize cost, and operational burden while guaranteeing high performance. One of the choices that reflects this is the selection of DynamoDB.
DynamoDB is a high-performant key-value store with document support, it provides filtering capabilities but to guarantee performance (and low cost) you need to be smart with your keys. Limit the set to be filtered so to say.
Keys in our read-model need meaning, these keys are used as identity so the client can fetch an object based on its identity.
The first reason why our keys need meaning: clients need to know what to ask for.
We use the identity as the primary key in the view-store (actually as an element of the primary key, but more on that later), you can't change your primary key (I did not work with all databases known to man, but all DB's that I worked with have this "limitation"). To tie back in with the renaming, a rename probably means changing its identity and therefore the need for updating the primary key. From the view-store perspective, this means removing the old record and inserting a new one.
The view-store does not contain the truth, it is a mere projection of the truth.
This means we consider the view store as volatile, meaning, we could drop this table and repopulate by replaying snapshot events. This feature has proven to be valuable during concept experimentation in our development environment.
We use a single-table design for the view store to reduce infrastructural complexity, mainly regarding system access management but also to support operations. Suppose your application receives a high load (congratulations) if that happens you could opt to switch from on-demand to provisioned capacity for this specific table. As stated in the DynamoDB documentation:
You should maintain as few tables as possible in a DynamoDB application. Having fewer tables keeps things more scalable, requires less permissions management, and reduces overhead for your DynamoDB application. It can also help keep backup costs lower overall.
How did we implement the single-table design, let's take a look at the view table in our staging environment:
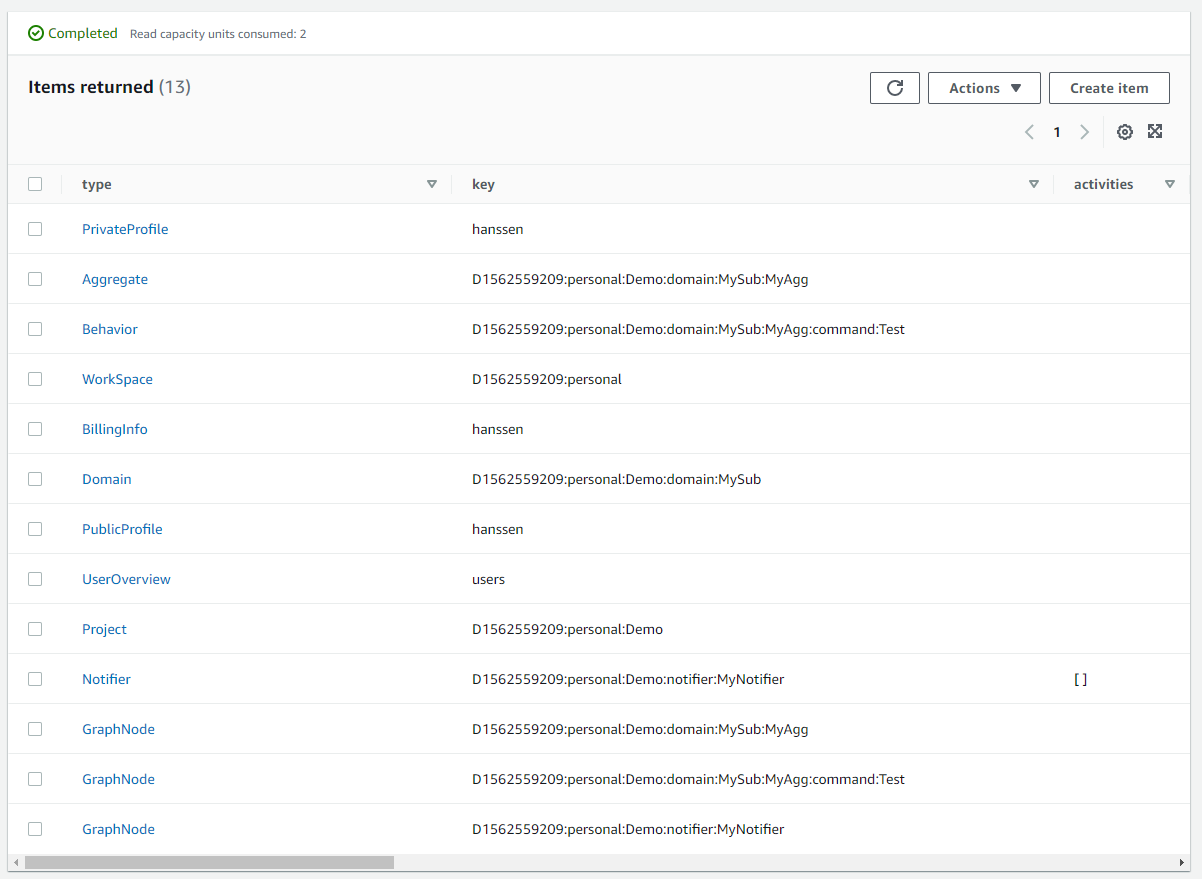
DynamoDB is a key-value store, but it does actually support the use of a 2-part composite key. This mechanism is used for the event stores and the view store, but let us focus on the latter.
We have a column named type, this is the partition key. A partition is a sub-collection within the view table e.g. if I would (I'll use pseudo queries for readability) select document where type == 'Project' and key == 'D1562559209:personal:Demo' I would receive a specific document.
The key field is actually a range-key, the unique identifier within this sub-collection.
If I fetch documents where type == 'Project' I will get the whole collection. Then I could filter this set to get all Projects that belong to a certain workspace.
But we can do it smarter, we model our views as nodes in a graph. The entities have relations with one another. For example, a workspace contains projects and projects have subdomains, etc. If we take a look at a GraphQL query:
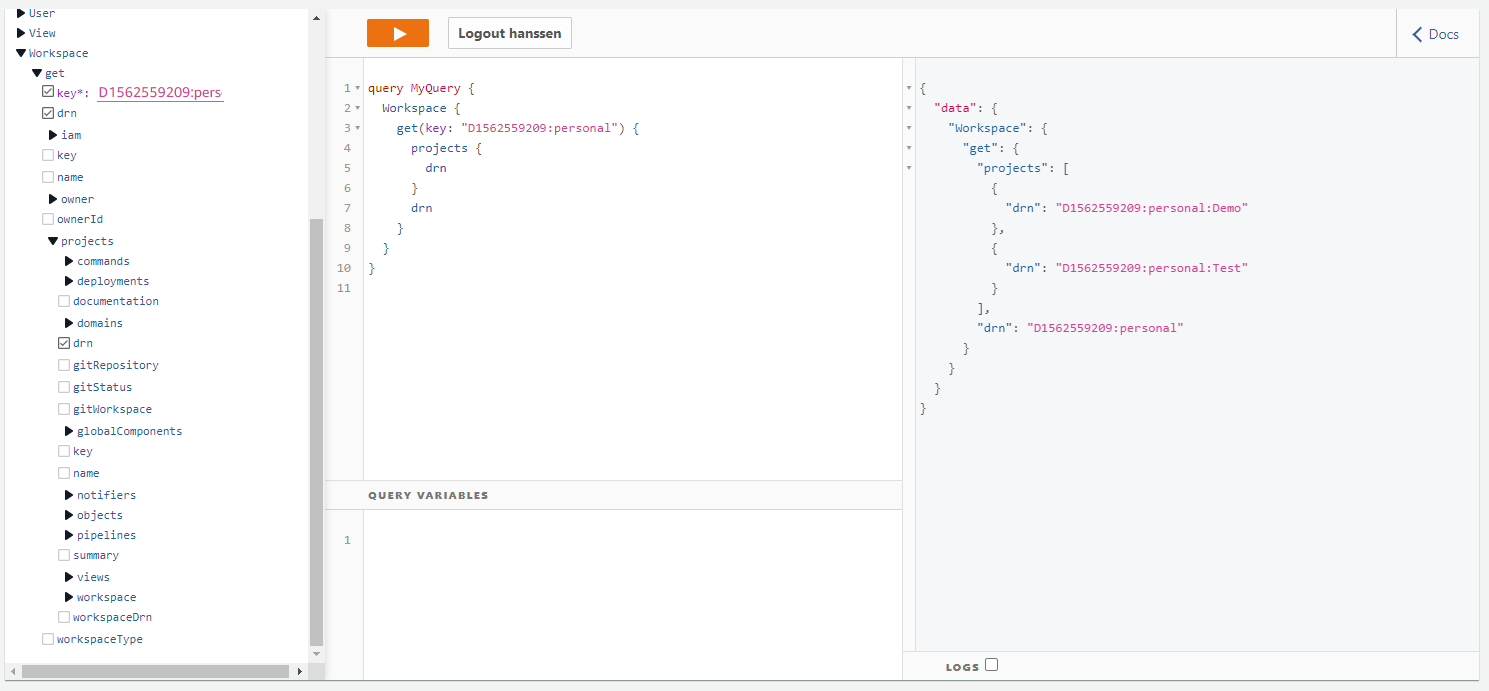
We get a workspace and within this document, we expect a collection of projects. as it is a GraphQL API we only retrieve the information we ask for. The result shown on the right side is not 1 document but the aggregation and filtering of 3 documents 1 Workspace instance and 2 Project instances. The GraphQL server "knows" it needs to perform a second query to fetch the projects (don't worry, that is one of the things we can generate). It would be wasteful to first fetch the whole Project collection to only filter it afterward. Luckily DynamoDB supports an alternative:
fetch documents where type == 'Project' and key begins with 'D1562559209:personal' providing faster response times and lower cost.
The second reason our keys need meaning is because we use them to model hierarchy and relations.
We call this a canonical-key (data architecture is not my field of expertise if you recognize this concept and know what it is called please send me a message at [email protected]). This canonical-key plays also an important role in our access management and the way we modeled multi-tenancy, but that is a post on its own.
The way this is set up means you don't have to worry so much about cyclic dependencies in your view model. This is demonstrated in the completely nonsensical next query.
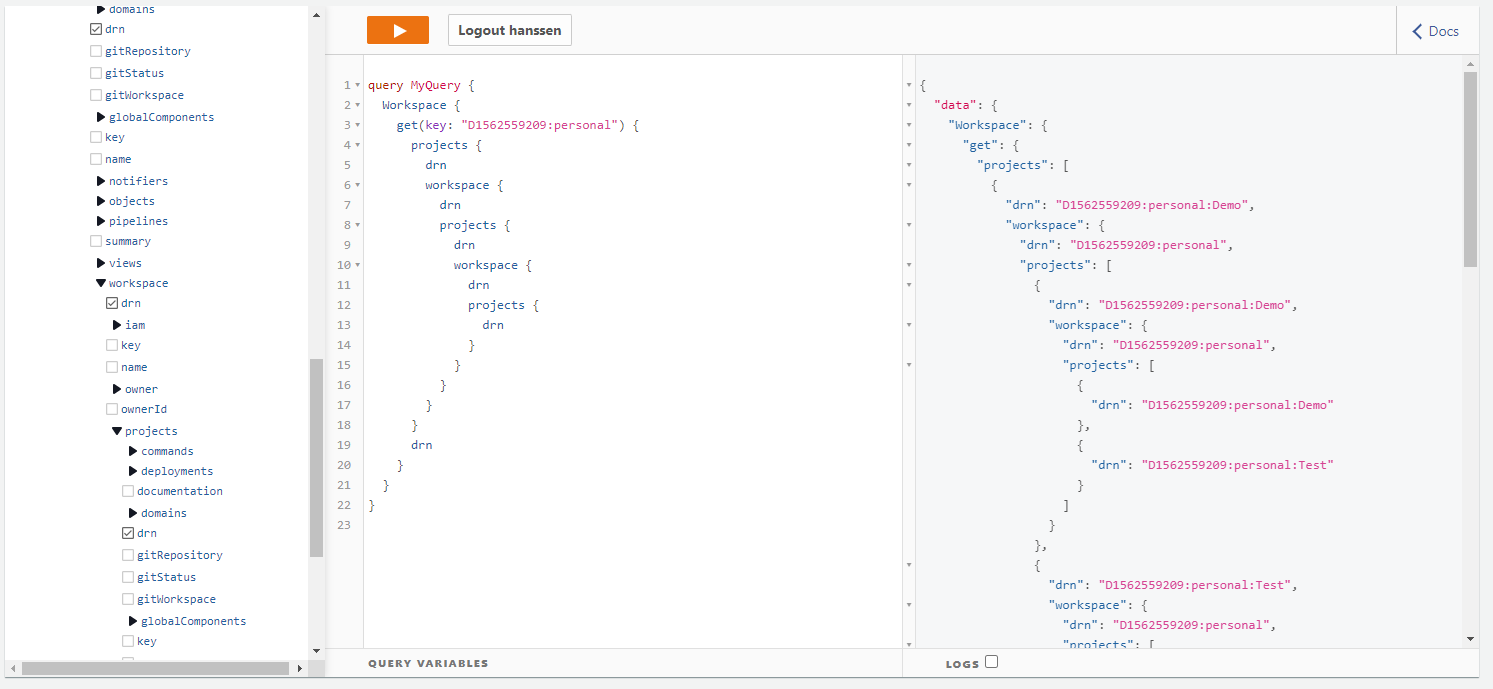
In this query, I traverse the relation workspace <-> project a couple of times in a cyclic manner. Not useful in this case, but it does work nonetheless.
So a lot of reasoning has to do with modeling relational data in a non-relational database. If the data is relational why use a document based database?
AWS does provide a serverless relational Database AWS Aurora. Two reasons why we didn't select it.
1. V2 was not generally available at the time we needed a decision (and V1 was not sufficient for what we wanted to do with it).
2. It was not serverless enough for us. It requires you to think about e.g. instance size. Secondly the pricing was not granular enough.
But Aurora sparks interest, so we do keep an eye on it for future updates.
Enough about querying and relations let us look at the write-model (the red stuff), the write-model is very much behavior driven. It receives events, executes some logic, and appends additional events. Determining state is the act of replaying all past events from a log. The aforementioned event log is long-lived and therefore we can't use the canonical-key from the view model. The canonical-key has meaning and therefore it can't be inmutable. When we change the meaning of things e.g. a rename because I am human and made a typo the first time it may cause the identity to be affected as well. So no canonical-key as primary in de event stores. If we ignore this we can't change the meaning of this key without corrupting the event log.
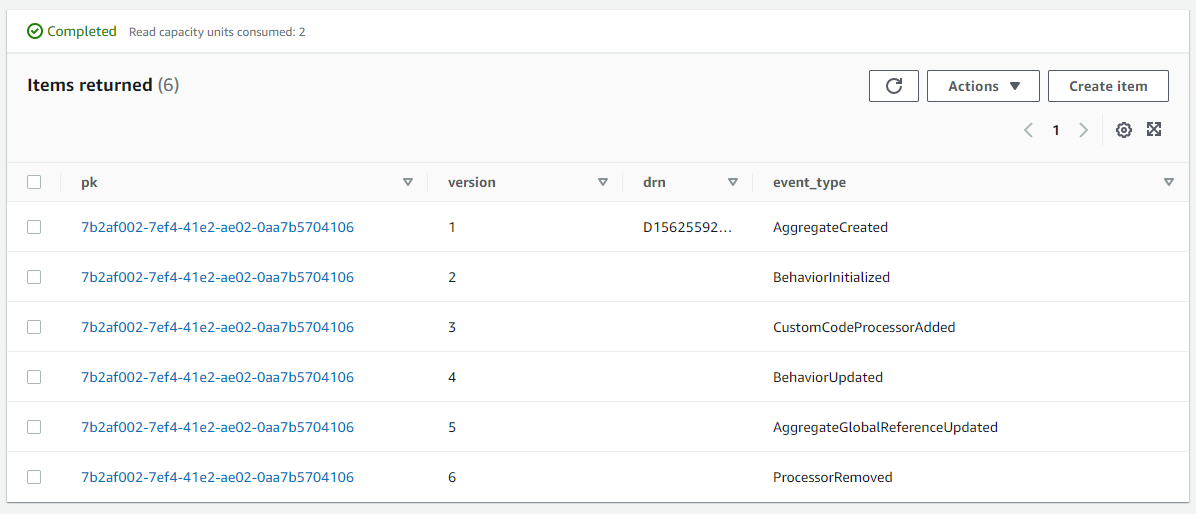
So the write model needs a technical key, so we chose a UUID-String. And if we take a look at the event store you can see clearly see that the primary key is a UUID, this is in fact the partition key (the collection) and for the range key, we use a version number. This way the program can retrieve the whole collection and replay the events to determine the current state. Because the pair must be unique we can avoid collisions with the aid of optimistic locking.
From the client's perspective, however, I don't want t know about these keys. They are technical, better word would be internal keys. From the GraphQL API perspective I wan't to use the meaningful canonical key:
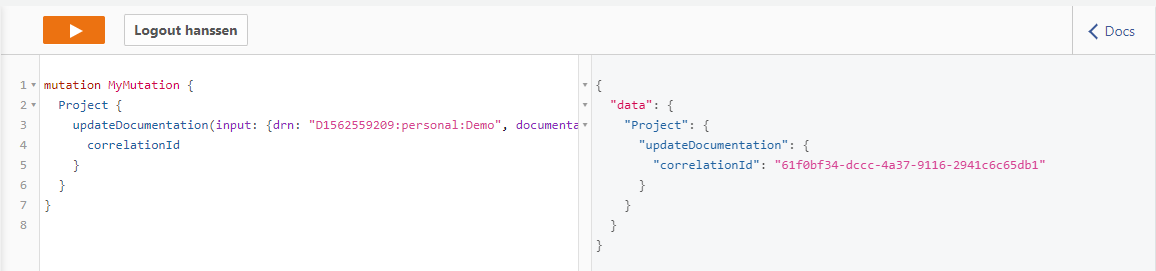
If we would take a look at Track and Trace:
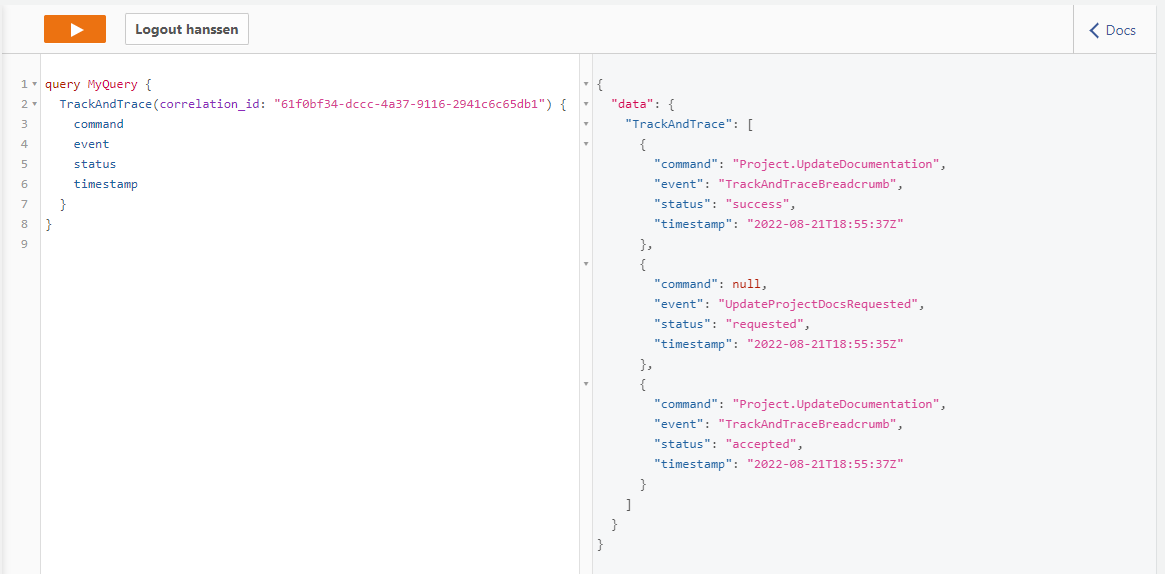
You will see that the update was successful, and in the project event store an event is added:
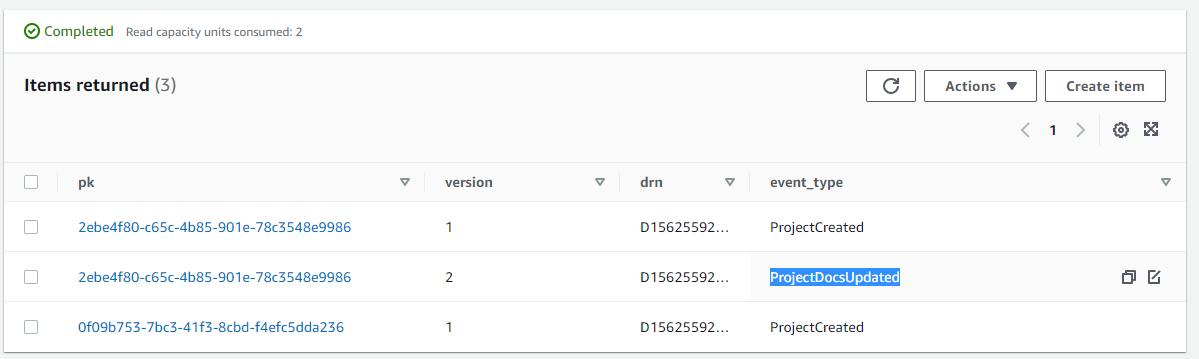
The application is perfectly capable to figure out how to translate the external key (canonical key, in our case the Draftsman Resource Name drn) to the internal key (UUID). To do this we introduced the key chain.
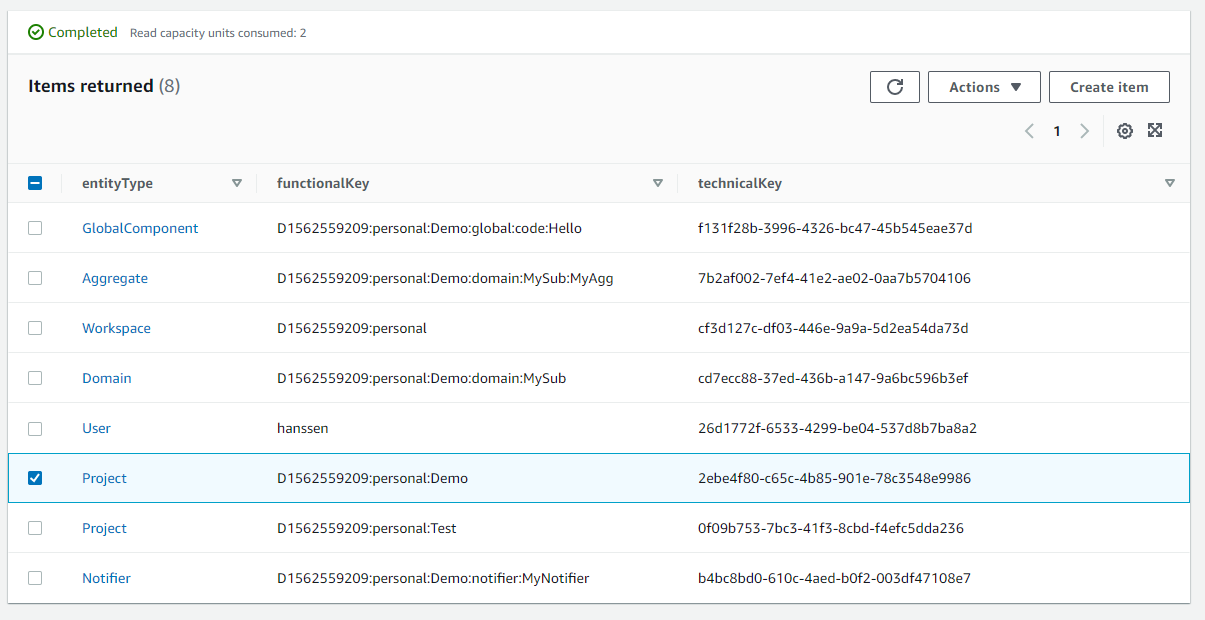
The best part, we compressed this into the Draftsman runtime. So you only have to worry about the functional keys (You don't have to design a canonical key, but it proved to be very beneficial for us.)
Why did I ramble on for 1000+ words on key design, query concepts and whatnot if it is abstracted away? Well, I had to explain why this feature is not as lame as it sounds right? ;)
But it hasn't all been champagne and caviar. Not everything is magically fixed with the addition of the key-chain, some things needed modeling e.g. the cleanup of deprecated view instances. After a rename, an event is thrown that causes a new insert into the view-store instead of the usual overwrite. So we needed to model view updaters to get rid of the deprecated view instance.
Secondly aggregates might reference each other, e.g. a behavior-flow references a command (because it is a trigger). This reference needs to be updated, and therefore we modeled notifiers (if-this-than-that) to "fix" this. I will not go into detail, for now, I should first finish the Modelling in Tracepaper series.
Comments and questions are welcome at [email protected]
Cheers!
Bo